📊 React 实践技巧和性能优化
!本篇文章过于久远,其中观点和内容可能已经不准确,请见谅!~
大部分的 React 开发是不需要考虑性能优化的,因为很多业务复杂度不需要这么苛刻的需求,常见的页面和交互都比较简单,展示型的组件除了长列表并没有太多性能问题。不过 React 这类框架生来就是能够搭建大型单页应用的,所以性能问题在这些应用级别的页面中还是很值得说道的。
好巧不巧,我在项目中就遇到了很多的性能问题,🌋 WebIDE 的开发记录其一(前言和概览) 业务模型很复杂,状态管理很复杂,很多组件更新频繁,实践了很多的性能优化的手段,这里总结下。
“卡顿” 是个很主观的感受,性能优化之前需要将这个事情量化,一定程度可以说 “卡顿” = “超过 16.67ms 不能响应操作或者执行渲染”,所以执行一个渲染或者计算的时间间隔可以判断界面卡顿。
另一方面性能优化不仅仅说优化到不卡顿,可能对于很多不必要的渲染和计算也是需求的一部分,还有交互和视觉方面的优化,比如首屏时间(First Contentful Paint)、主要内容时间(First Meaningful Paint)、可响应时间(Time To Interactive)、用户响应和组件渲染的协调、状态派发和订阅机制等等,优化了之后能有更流畅的体验,这就是更高质量的要求。
- Chrome Dev Tools / Performance / Lighthouse ,和传统的方式一样,而且也能找出大部分的性能瓶颈;

Chrome Performance - React Profiler React 内置的,可能不是很准确,但是重点度量渲染过程中的开销;

React Profiler
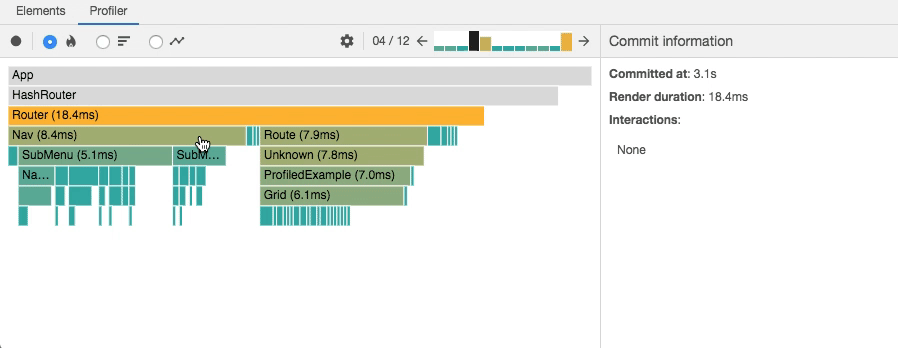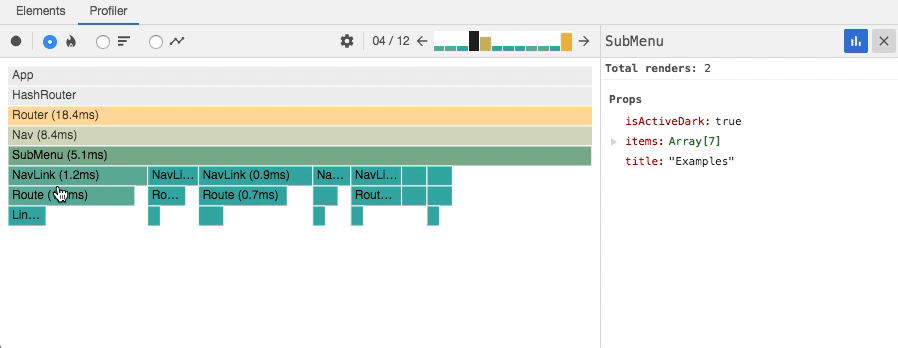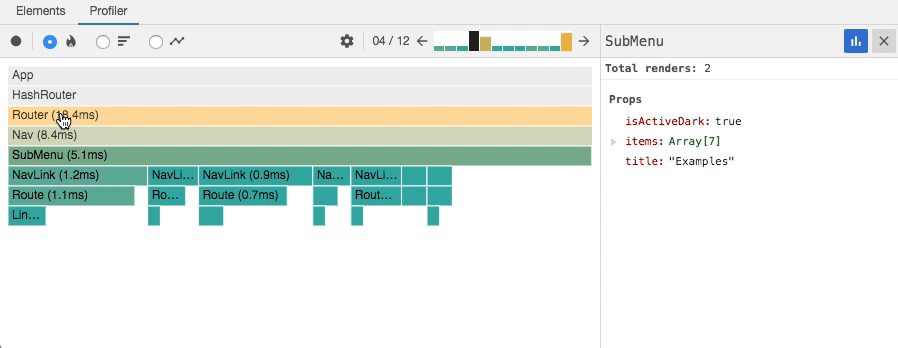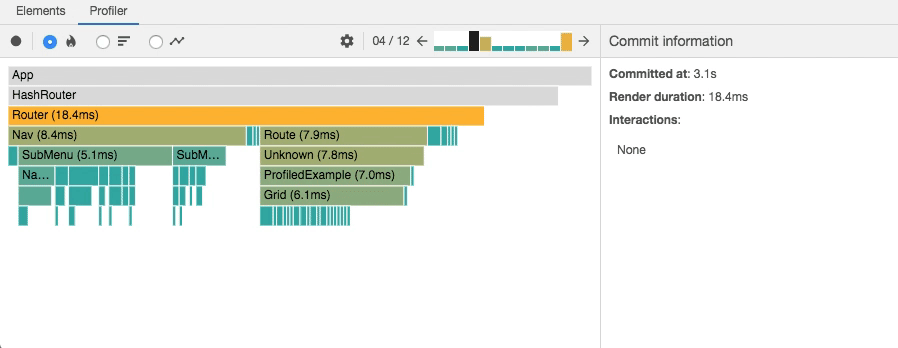
- User Timing 使用较高精度的接口手动测量一些开销,React 内部也是使用了这个接口可以在浏览器的 Performance 中聚合组件的信息;
- Puppeteer 可以忽略 UI 渲染,手动测量一些计算的开销;
以上的工具能够调试到常见的时间花销,能够帮助找到那些耗时的函数或者组件,能解决大部分问题。
- 渲染
- 首屏渲染。从用户打开页面,到页面内主要内容展示出来的时间
- 响应渲染。用户的操作在界面上展示的响应,切换 tab 展示新的内容
- 网络
- 网络的速度也是非常影响用户的耐心,用户的平均上网速度已经很快了,如果你的网站加载页面或者响应查询的时间有点长,用户可能就会怀疑可能出现了什么问题。
- 后端传统的做法:负载均衡、CDN、HTTP/2、查询缓存、图片压缩、webp 等手段
- 前端能做的:本地缓存、http 请求缓存、localStorage 缓存、service worker、PWA、预加载数据等可以非常有效的优化网络问题(这块也很值得深入)
- Preload、Prefetch、Preconnect 提前进行预连接以避免 DNS、TCP 以及 TLS 往返延迟
- 使用渐进式的图片、代码拆分等分阶段加载和展示内容
- SSR 服务端预渲染
- 计算
- 前端的一些操作可能会占用 JavaScript 的计算资源
- 比如包体积、动画、频繁响应 scroll 或者 mousemove 事件,或者不必要的计算
类 React 框架相比较传统的页面都比较弱一些,因为一般不做优化,首屏渲染肯定比预渲染的慢得多,而且包体积较大影响网络传输,最后每个组件都要先计算出来才能通过 virtual dom 到真实界面上。
有这些方面的因素,但是具体到每一个优化点都有很多的实践,一般的项目选择最适合的即可,要求苛刻的在这上面做到极致也是很不容易的。常见的优化方法:
- 减少不必要的计算和渲染
- 降低状态变更的影响范围
- 调度计算以避免同时阻塞
我认为性能的极致优化更应该融入在一般编码过程中,而不是严重依赖于事后的度量和专项优化。因为很多的不必要的计算,是因为没有理解整个框架的流程和机制,可能业务优先的时候并不顾的很多最佳实践。
比如添加一个 prop 参数传递你第一时间想的是子组件用得到,而很少去考虑这个参数对子组件的重复渲染有多大影响。
聚焦到 React 这一个框架上,有很多的思维形式和传统的组件化不同,这里着重说一下:
React 或者类似的订阅更新机制,最忌讳的就是大粒度的订阅触发,而 React 响应式的根本也是依赖于此,大组件或者状态多的组件就会导致频繁状态变更导致的渲染。
React 更依赖于 state 的更新,所以需要将频繁变更的 state 转移到子组件来隔离变更。
这个是最基础的重复渲染优化逻辑,告诉 React 哪些变更是不会影响组件的表现的,以跳过渲染运算的逻辑 UNSAFE_componentWillUpdate、render、componentDidUpdate 都将不会执行。
使用上直接在 shouldComponentUpdate 的生命周期中比对 this.props 和 nextProps 以及 this.state 和 nextState,返回 false 声明本次渲染的逻辑到此不必向下进行了。
shouldComponentUpdate(nextProps, nextStates) {if (nextStates.count === this.state.count) return false;if (nextStates.count2 !== this.state.count2) return false;return true}
开发的时候如果传递的状态值只是中间过程、或者频繁变动、或者可以不更新界面之类的情况,可以在此处统一处理。
先看生命周期很清晰的
React.Component 组件:- 自身状态变更 / 传递属性变更 就会导致重新渲染。即使状态没有被使用,即使状态值没有变动。
- 父组件渲染会导致子组件重新渲染。即使父组件的状态变更没有涉及子组件的依赖。
Component 会出现不必要的渲染问题,而平时推荐的另一个组件
React.PureComponent:- 如果状态没有被使用,或者状态值没有变动则不会重新渲染。
- 父组件的状态变更没有涉及子组件的依赖,或者传递值没有变化,子组件就不会变动。
PureComponent 相比 Component 性能更好些,因为在 props 和 state 变动之后,PureComponent 使用 浅对比 的逻辑实现 shouldComponentUpdate 计算成本非常低但是很有效的性能优化。
不过需要注意的是,可能有时候对象深层数据不一致导致需要渲染的时候没有更新界面,或者相同属性的不同对象被判断为不同的值引发不必要的渲染。
上面说了 PureComponent 的优化,涉及到浅比较,下面是核心的逻辑:
if (this._compositeType === CompositeTypes.PureClass) {shouldUpdate = !shallowEqual(prevProps, nextProps) || ! shallowEqual(inst.state, nextState);}
其中 shallowEqual 源码:
function shallowEqual(objA: mixed, objB: mixed): boolean {// 最简单的浅层比较if (Object.is(objA, objB)) return true;// 一些边界条件和简单类型数据判定if (typeof objA !== 'object' ||objA === null ||typeof objB !== 'object' ||objB === null) {return false;}// 下面深入比较const keysA = Object.keys(objA);const keysB = Object.keys(objB);// 如果属性长度不同if (keysA.length !== keysB.length) return false;// 接下来遍历属性比较,计算可能较多,所以放到最后。属性差异,或者两者同一个属性不相等for (let i = 0; i < keysA.length; i++) {if (!Object.prototype.hasOwnProperty.call(objB, keysA[i]) ||!Object.is(objA[keysA[i]], objB[keysA[i]])) {return false;}}return true;}
用几个例子就能知道:
所以对于传递数据是基础数据类型的值,无脑用 PureComponent 就行了,对于引用相同的数据结构构,则可能出现视图无法更新问题,需要自己处理比较的部分或者使用 immutable 的处理方式。
- 可能频繁执行的纯函数的输出,不应该包含副作用和可缓存的重复计算。render 在组件意义里面表示的是构建视图层的逻辑,存在的意义仅在于根据现有的状态和数据输出组件内容。在此意义上来讲,这就是个纯函数组件,不应该出现副作用或者更新状态之类的逻辑,更不应该存在能够缓存的计算,仅应该出现输出相关的部分,如果有计算属性比如需要计算 10000 多个人的平均身高,不应该在 render 里面计算,而应该在变更的时候计算出结果缓存起来再 render。
- render 的执行完毕仅表示组件逻辑交给了 react,绘制到界面是由 react 接管的。render 函数并不是直接输出界面内容的,而是仅输出一个描述结构,然后 react 框架接管调度到虚拟 DOM 最后才会在界面上看到结果。
这里想表达的是 props 和 state 存在的意义完全不同,但是变更都能导致组件渲染。props 和 state 如无必要尽量少设置,而且每一个值都要进行变更逻辑优化,比如每次渲染是否会变更,是否使用了经常发生变化的引用值之类的。
比如下面示例 columns 和 onSelect 每次 render 的时候都会变更,都是没有必要的:
class TableDemo extends React.Component {getColumns = () => {return [{ key: 'name', title: '姓名' },{ key: 'age', title: '年龄' },{ key: 'more', title: `${this.state.action}操作` },];};render() {return <Table dataSource={this.props.data} columns={this.getColumns()} onSelect={(key) => this.onSelect(key)} />;}}
state 是组件的状态;props 是组件的接口;state 的存在是为了保存让 UI 响应变化的属性,与内部相关,可以根据不同的逻辑进行变更修改。props 的存在是为了接收外部的状态能够影响 UI 的输入,是单向传输不可以修改的。对于没有外部副作用的组件,state 和 props 能够确定一个组件的表现。
props 和 state 确定组件表现最常见的一个例子:受控组件。一个表单组件,外部输入初始值,内部维护真实值,然后通过外部的监听函数反馈状态变更,单一数据源原则。
官方也深入的说了这个问题: 你可能不需要使用派生 state。
componentWillReceiveProps 是差不多的思想,就是在 props 变更的时候运行,不同的是 getDerivedStateFromProps 是一个新的接口,而 componentWillReceiveProps 已经废弃了,为什么废弃暂且不说。
这个周期函数一般是很不建议使用的,因为这个函数钩子存在的目的在于:让某个 state 完全依赖与 props 的变更,让组件在 props 变化时更新 state,除此之外不应该使用这个接口。比如 props 的 offset 变化时,修改当前的滚动方向和根据 props 变化加载外部数据。
为什么这么强调呢,因为上面提到的原则,state 是内部的,props 是外部的。不应该下面这两种情况,实际上很多实践都是这么干的:
- 直接复制 props 到 state 上;
- 如果 props 和 state 不一致就更新 state。
这么做没问题,但是经常会出现一些思想上的问题:
- 受控/非受控组件。如果 state 根据 props 改变,同时还能根据用户操作改变,那么就会出现不一致的体验。比如表单中 props 控制显示还是 state 控制显示的统一。
- 只要父组件重新渲染,子组件的这个函数就会被调用,无论有没有 props 有没有变更,然后 导致不必要的计算。
class ExampleComponent extends React.Component {state = {externalData: null,};static getDerivedStateFromProps(props, state) {// Store prevId in state so we can compare when props change.// Clear out previously-loaded data (so we don't render stale stuff).if (props.id !== state.prevId) {return {externalData: null,prevId: props.id,};}// No state update necessaryreturn null;}componentDidMount() {this._loadAsyncData(this.props.id);}componentDidUpdate(prevProps, prevState) {if (this.state.externalData === null) {this._loadAsyncData(this.props.id);}}componentWillUnmount() {if (this._asyncRequest) {this._asyncRequest.cancel();}}render() {if (this.state.externalData === null) {// Render loading state ...} else {// Render real UI ...}}_loadAsyncData(id) {this._asyncRequest = loadMyAsyncData(id).then(externalData => {this._asyncRequest = null;this.setState({externalData});});}}
耗时计算的缓存
上面说了受控非受控组件,尽量不能直接将 props 复制到 state 的实践原则,那么怎么才能将复杂的 props 计算缓存以避免复杂的计算?
import memoize from "memoize-one";class Example extends Component {// state 只需要保存当前的 filter 值:state = { filterText: "" };// 在 list 或者 filter 变化时,重新运行 filter:filter = memoize((list, filterText) => list.filter(item => item.text.includes(filterText)));handleChange = event => {this.setState({ filterText: event.target.value });};render() {// 计算最新的过滤后的 list。// 如果和上次 render 参数一样,`memoize-one` 会重复使用上一次的值。const filteredList = this.filter(this.props.list, this.state.filterText);return (<Fragment><input onChange={this.handleChange} value={this.state.filterText} /><ul>{filteredList.map(item => <li key={item.id}>{item.text}</li>)}</ul></Fragment>);}}
答案就是使用 memoize 缓存计算,可以直接使用 props 的值,但是不必计算额外的 state。这个思想也是很多极致性能的一个很重要的实践。
在 React 函数中可以使用
useMemo 来缓存计算。函数组件的缓存
父组件和本身的状态决定一个组件是否要重新渲染,但是很多的组件渲染并没有必要。
class 组件本身能够拦截渲染函数,最终也能被 shouldComponentUpdate 拦截这个渲染决定,有自己的主权。但是函数组件只要流程走到函数组件这里,那么整个函数本身就会执行到底,包括其中的子组件,如果不加任何控制,根组件的一个状态变更,全局的全部组件都会渲染,造成非常大的卡顿。
函数组件有没有类似 PureComponent 或者 shouldComponentUpdate 的东西呢?
React.memo 这个东西能够代替前两个的作用。React 有顶层的函数接口
React.memo 来实现组件级别的缓存,可以保证在相同的 props 输入情况下渲染相同的结果,缓存组件的计算。const MyComponent = React.memo(function MyComponent(props) {/* 使用 props 渲染 */});
需要注意的是这里的 props 相同 还是上面说的【浅比较】,不过可以通过第二参数指定比较函数:
function MyComponent(props) {/* 使用 props 渲染 */}function areEqual(prevProps, nextProps) {/*如果把 nextProps 传入 render 方法的返回结果与将 prevProps 传入 render 方法的返回结果一致则返回 true,否则返回 false*/}export default React.memo(MyComponent, areEqual);

分清哪些是状态变更、哪些是副作用、哪些是不必要的计算。生命周期在组件的挂载、更新和销毁时都会执行对应的钩子函数,所以区分具体的生命周期,弄清副作用,然后缓存耗时的计算,在合适的生命周期中做正确的事情。
在完善了不必要的计算和缓存之后,考虑整个用户界面交互的全局节奏来看,性能问题本质上其实是调度问题,如何调度 IO 和 CPU 任务? 比如现在想要计算渲染多个组件、网络正在获取数据、用户正在点击某个按钮这些任务,如果一股脑的全塞给 Call Stack,可能会出现组件渲染占用太多时间没有相应用户点击,可能会出现渲染卡在了网络数据的等待上之类的广义上的性能问题。
这块可能并不是编码过程中需要涉及到的,但是其中的思想还是很值得了解下,从 Fiber 和 Scheduler 能看到 React 在整个渲染过程中的计算任务调度。React 除了提供了一套响应式的编程体验框架能力,还考虑到了在这个框架下的重度计算优化问题,因为从小到组件,大到应用的尺度上,再加上组件的层级封装,任何的遍历和递归渲染都可能涉及到不可控的 CPU 执行时长。
Fiber 是让组件的计算分片式执行,目的是避免组件渲染过程中占用太长时间的 CallStack,导致无法响应的问题,让渲染任务能够根据调度,能够被打断终止,实现计算过程中权利的控制,可以理解为 React 接管一定时间后主动将计算调度权利交给浏览器响应用户操作。
所以 React 通过 Fiber 架构,让自己的 Reconcilation 过程变成可被中断。'适时' 地让出 CPU 执行权可以及时响应用户操作、延时操作 DOM、让浏览器的运行更好的编译优化。
scheduler 用来做任务调度,实现 time slicing 最核心的功能,让 React 可以随时暂停、恢复某一个组件的渲染,实现比如 Suspense 等渲染暂停效果的功能。
📦 改进一个简单朴素的 react 数据管理层 NOVUS 文章中因为同步执行,可能导致的阻塞,对应的喘息机制是更简单的模型,与之类似。
上面的知识里面说了很多,这里简单列出来:
- React.PureComponent 避免不必要的重新渲染
- 将参数传递和内部状态尽可能拆分为基础数据类型
- React.memo 缓存函数组件,memoize 缓存计算
- 节流(throttling)和防抖(debouncing)
- 在复杂的状态和参数组件中使用 shouldComponentUpdate 拦截不必要的更新
- 懒加载、包拆分、公共依赖拆分等手段提升加载性能
- 避免在 props 中传递内联匿名函数,以及动态获取数据逻辑
- 把请求等副作用部分放到 componentDidUpdate 和 componentDidMount 钩子函数中
- 最好在构造函数中绑定 this,不济也可以使用 属性等于箭头函数
- 列表组件添加唯一 key
- 不可变数据结构 immutable
- 使用 SSR
性能的优化就是要减少不必要的加载、计算、渲染等,所以缓存、延迟、预加载等手段都是一样的套路。
感谢您的阅读,本文由 Ubug 版权所有。如若转载,请注明出处:Ubug(https://ubug.io/blog/react-pratice-and-performance)